
Amazon AWS is a very rich infrastructure. It is not uncommon for AWS to field several different yet somewhat similar types of services. The area of data storage is one of those areas where there is a rich set to pick from. Not all services are suitable for all tasks but when data needs to be stored there are quite a number to choose from.
- S3
- Elastic File System – EFS
- Elastic Block Store – EBS
- Amazon Glacier
In this post I will be examining S3 to demonstrate setting it up as well as discussing some of it’s uses.
First of all, S3 is not a file system but it can also be mounted as such. Amazon created S3 as a place where you can store whole objects and these objects (pictures, pdf’s, videos) are what most users would consider to be an actual file. The difference in how S3 treats these objects becomes obvious when there is a change in the object.
A normal file system might be able to change one or two blocks of the file that encompass the change but for S3 the entire object is rewritten to the object store. This isn’t anything too dramatic unless you have a lot of objects constantly under change or have very large objects such as database backups or large videos.
Perhaps to try and keep the S3 distinguishable from their other options, Amazon has given the name of their S3 “devices” the name of bucket. Which to most users won’t be confused with hard drive or disk drive.
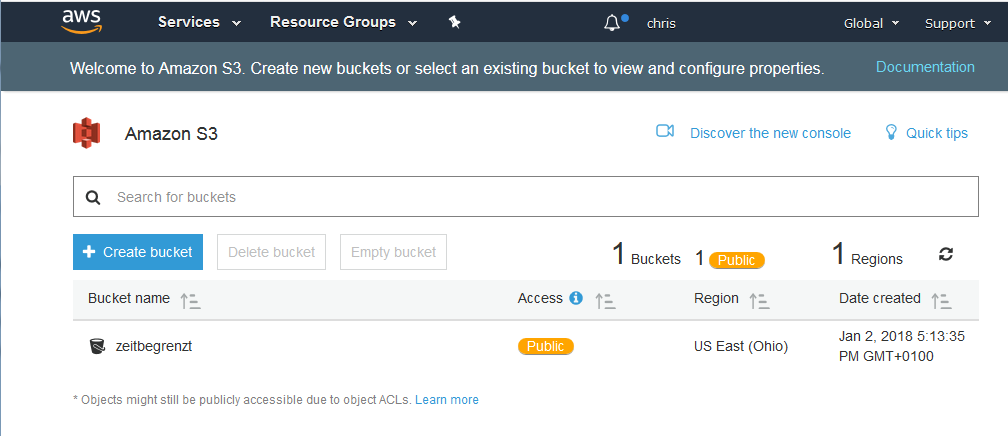
Setting up a bucket
The process of setting up a S3 storage bucket is really just a matter of a few clicks. Before you do so there are a few small details that must be considered before starting.
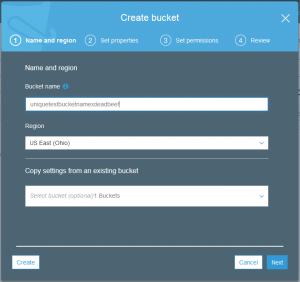
The most important detail is what is the name of the bucket. This is more important than the normal “computer” reason of good naming makes using it easier. The reason is that despite a bucket being associated with a specific region the name of the bucket must be unique for all buckets in S3 worldwide.
You also need to know which region your data should be stored. There doesn’t seem to be any limitations on accessing this data regardless of the region. A few of the reasons that the region might be important depends on the company or personal situation.
- close to clients who will access data
- stored in a specific region for legal reasons (ie. EU data privacy)
- stored in a specific region for safety reasons (far away for catastrophe concerns )
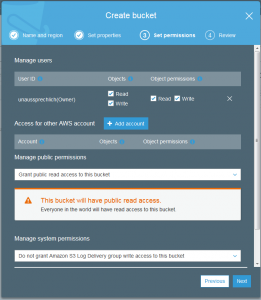
Does the data need to be encrypted and who should be able to access this data are the final important questions.
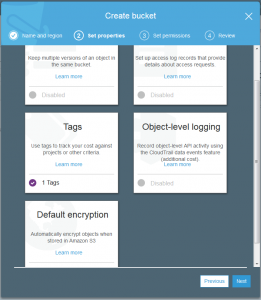
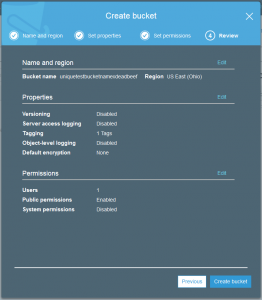
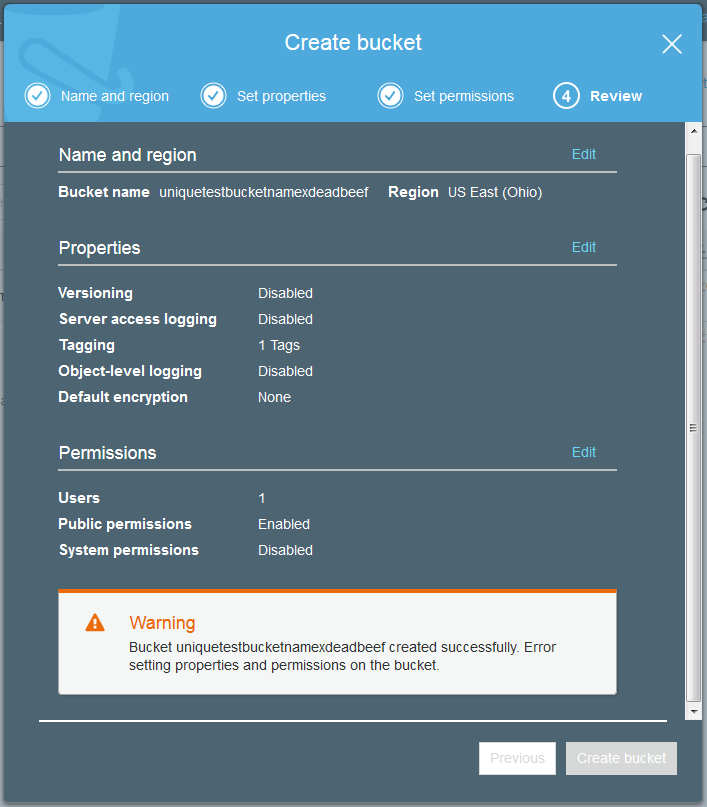
Just like many of the AWS services it is possible to set tags on the various objects you create. This might be a tag on the bucket or a tag on an uploaded data file. Tags are not so useful for the sake of description but are helpful to try and discover where exactly the costs are being used when examining your bill.
Uploading an object
Actually uploading a file is as simple as saving a file on your personal computer but does contain a few elements from the bucket creation. The important elements are storage class, encryption, tagging, and permissions.
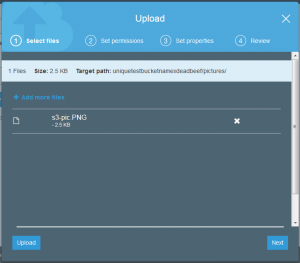
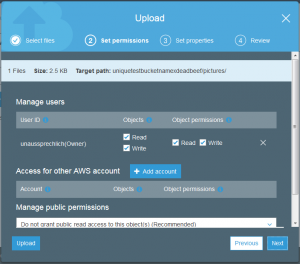
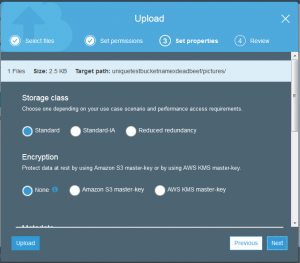
The good news is that the file is uploaded but if you took a close look at the permissions of the uploaded file, it is not actually possible for anyone else to read this but my account.
Simply go back to the file and change the permissions so this file is public.
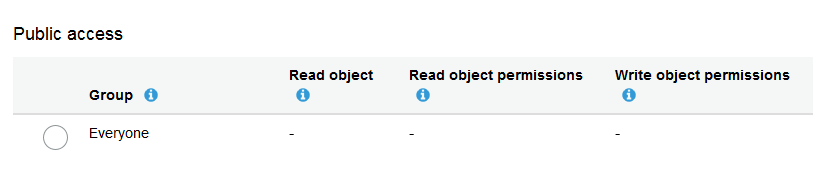
Permissions before
Permissions after
Once this small permission change is completed then it is possible to access this file from the S3 bucket as an average user with no AWS account.
It is interesting to note that there are two different layers of permissions and if both of them do not allow a normal person to access the file you will receive a 403 error when trying to access this object.
Other features of S3
Object versioning
This is by no means the end of the story for S3 buckets. It is also possible to enable file versioning. This is not totally unique in the history of computer science to have such a “file-system” with versioning. This was also implemented RSX-11 and OpenVMS which simply stored (VMS) a simple ordinal number with the file that was increased with each successive new file of that name.
I am not planning on discussing the versioning that Amazon provides but there are a number of different videos available on YouTube. It is interesting that Amazon provides such a long unique identifier. It is possible that this identifier is unique across all versioned files that are saved in S3.
Notifications / events
It is possible to publish notify events when something occurs in your bucket. It is also possible to have a lambda function use this event as its input. Depending on how you are using S3 it is also possible to use the life cycle rules to transition the data to a different storage class after a certain period of time. Likewise it is also possible to expire objects or delete expired objects after a given period of time.
Finally it is possible to replicate your data to other regions as well as gather analytics and metrics for your bucket. This information could be used in reporting.
Parting shot
S3 is really pretty amazing and despite the fact it doesn’t have elastic in the name is is a pretty elastic service. It does provide a nice place to save rather static data but it does have one thing going for it that may easily overlooked – it is as big as you need it to be.
You are allowed to have objects between one byte and 5 terabytes in size. This is pretty huge but it will automatically scale in the background. It is not a disk with a fixed size, it is a work-space that you can store an unlimited number of objects that can be really quite large.
Although I haven’t done it, it makes you wonder if this would be an interesting replacement for other services that allow you to have a “virtual disk” on the internet. The pricing is fairly cheap.
I currently use another service for sharing videos of family events but after looking at the aws pricing it might be possible to reduce my costs.
Your mileage may vary but if the files are not heavily accessed nor super large this might be an alternative.
